Eindrucksvolle Charts für die nicht verstummenden Fraktionen der linearen Ausbreitung sowie der zu hohen Testzahlen: Das ist in der Tat nun schlicht unstrittige reine Mathematik ohne jeden „Meinungsspielraum“.
In Chart 1 wird der Reproduktionsfaktor R aus den Daten mittels des Kalman-Filters geschätzt. Man kann nun gerne diskutieren, ob diese Schätzung den Verzug zwischen den Meldedaten und dem Infektionszeitpunkt gut bestimmt oder nicht. Was aber nicht diskutierbar ist: Wenn diese Daten tatsächlich jemals linear verlaufen wären, so müsste der Wert stabil und sehr nah bei Eins liegen. Das war zu keinem Zeitpunkt der Fall. Diese Daten sind stets nonlinear gewesen – auch im letzten Sommer!

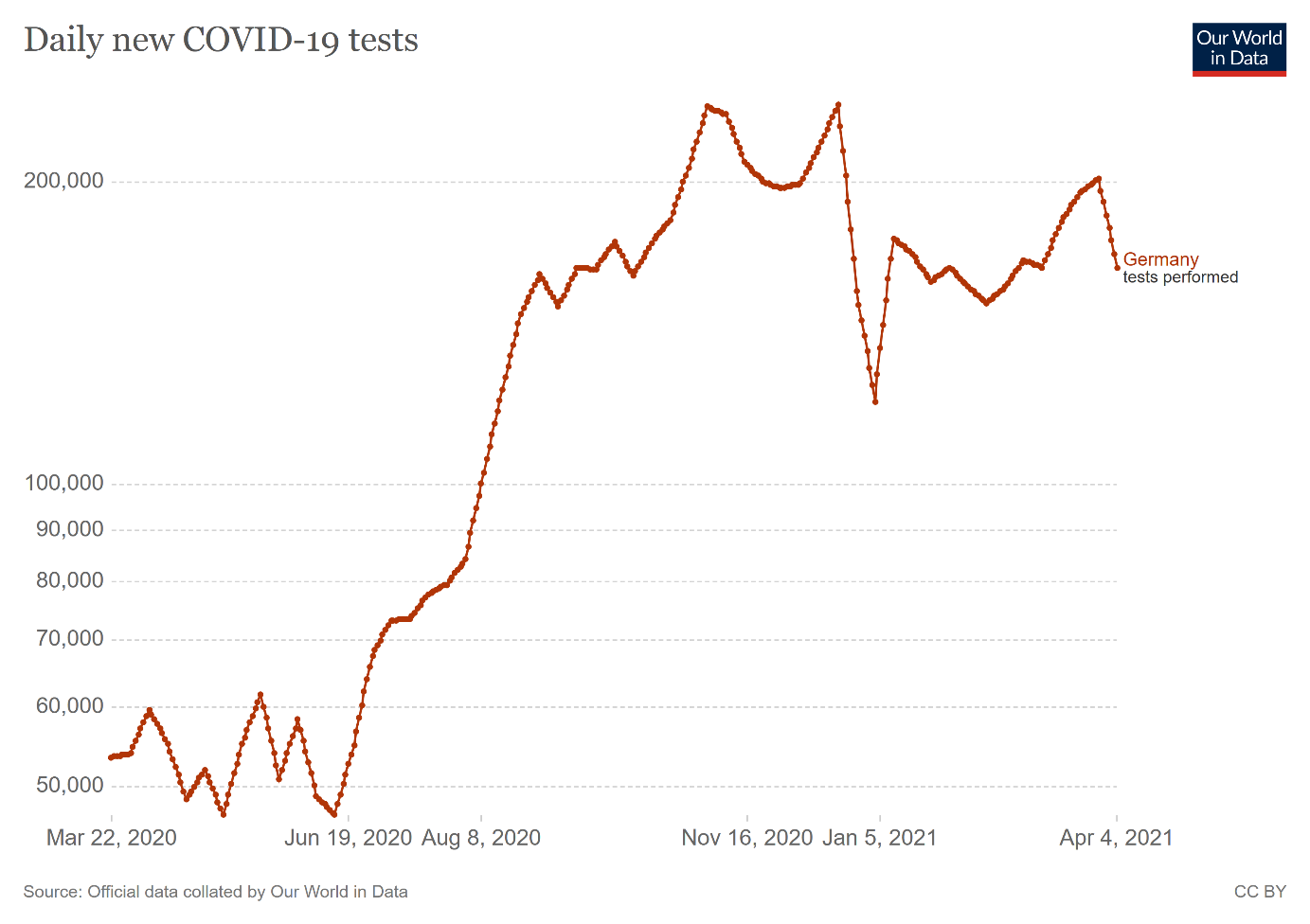
Einmal mehr wird ferner bewiesen, dass die Testmenge (2. Bild) auf diese Daten keinen steigernden Einfluss hat, denn die Testmenge ist während der ersten Welle stabil gewesen, VOR der zweiten Welle (Testungen der Urlaubsrückkehrer) viel stärker als die Infektionszahlen gestiegen und dann zwei Mal (Weihnachten und Ostern) massiv eingebrochen, was anhand der klinischen Daten nachweisbar zum Ausbruch der Dunkelziffer geführt hat.
Daraus ist klar erkennbar: Viel testen senkt die Dunkelziffer, wenig testen erhöht sie und ergibt zu NIEDRIGE Infektionszahlen.
Natürlich widerlegen diese Daten nicht das Schwurbeltheorem Nummer 1, demzufolge die Tests entweder überwiegend falsch sind, keine wirklich kranken Menschen erfassen oder ähnliches. Nun, dazu kann man nur sagen, dass die gemeldeten Infektionszahlen auch wenn sie vom Himmel fallen, gewürfelt werden oder von verschwörerischen dunklen Kreisen „diktiert“ sind: Sie sagen präzise voraus, was zwei Wochen später auf den Intensivstationen unserer Krankenhäuser los ist.
Man mag insofern über ihre Entstehungen schwurbeln, was man will: Die Bedeutung der Daten ist leider auch unstrittig.